Pandas Python: o que é, para que serve e como instalar a biblioteca pandas para análise de dados


Se você pesquisou algo como "pandas python", "o que é pandas", "como instalar pandas no python" ou "biblioteca pandas em python", provavelmente está começando sua jornada em análise de dados ou buscando entender como a biblioteca pandas pode facilitar seu trabalho com dados.
E você veio ao lugar certo! A Ciência de Dados é uma área que cresce exponencialmente, impulsionando decisões estratégicas em empresas de todos os portes, desde startups inovadoras até gigantes como Netflix, Airbnb e Google.
Nesse cenário dinâmico, a linguagem Python se destaca pela sua versatilidade e simplicidade, oferecendo um ecossistema robusto de bibliotecas poderosas.
Entre essas bibliotecas, uma delas se destaca como ferramenta indispensável: o Pandas.
Neste artigo, você vai descobrir o que é a biblioteca pandas em Python, para que serve, como funciona e, principalmente, vai aprender como instalar o pandas no Python de forma simples e prática.
O que é Pandas Python? Entenda a biblioteca pandas em Python
Quando falamos em "biblioteca pandas python", estamos nos referindo a uma ferramenta de código aberto construída sobre a linguagem Python.
Ela oferece estruturas de dados rápidas, flexíveis e robustas, projetadas especificamente para trabalhar com dados relacionais ou rotulados.
Tudo isso de uma maneira surpreendentemente simples e intuitiva.
Apesar do nome "Pandas" nos remeter ao adorável mamífero, a origem do termo é bem mais técnica. O nome Pandas deriva de "Panel Data", um conceito da econometria que utiliza métodos estatísticos na economia.
Curioso, não é? Assim como o Python não tem relação com cobras, o Pandas também não se refere ao animal, mas ambos são poderosos em seus respectivos contextos.

Para que serve a biblioteca pandas e principais aplicações
O Pandas é um verdadeiro canivete suíço para quem trabalha com dados. Suas aplicações são vastas e vão muito além do básico.
Veja algumas das principais atividades e processos onde o Pandas se destaca:
- Limpeza e tratamento de dados: Dados do "mundo real" raramente vêm perfeitos. O Pandas é excelente para lidar com valores ausentes, tratar dados, remover duplicatas, corrigir formatos inconsistentes e padronizar suas informações, preparando-as para a análise.
- Análise exploratória de dados (EDA): Antes de mergulhar em modelos complexos, é interessante entender o que seus dados estão dizendo. O Pandas permite explorar distribuições, identificar tendências, correlacionar variáveis e extrair insights valiosos rapidamente.
- • Suporte em Machine Learning: Na construção de modelos de Machine Learning, o preparo dos dados é uma etapa fundamental. O Pandas ajuda a organizar e formatar os conjuntos de dados para que bibliotecas como Scikit-Learn possam processá-los eficientemente.
- • Consultas em bancos de dados relacionais: Embora não seja um banco de dados, o Pandas pode interagir com eles, permitindo que você execute queries e manipule os resultados diretamente em Python.
- • Visualização de Dados: Em conjunto com outras bibliotecas como Matplotlib, Seaborn e Plotly, o Pandas facilita a criação de gráficos e visualizações impactantes para comunicar seus achados de forma clara.
- • Web Scraping: Para coletar dados da web, o Pandas pode ser um aliado, ajudando a estruturar as informações extraídas em formatos que podem ser facilmente analisados.
Além de suas funcionalidades intrínsecas, o Pandas tem uma integração fantástica com outras bibliotecas populares da Ciência de Dados, como:
- NumPy (para computação numérica),
- Scikit-Learn (para Machine Learning),
- Seaborn,
- Altair,
- Matplotlib e Plotly (para visualização),
- SciPy (para computação científica).
Isso cria um ecossistema completo para qualquer projeto de dados.
Quer entender ainda mais sobre as características e a capacidade do Pandas? Temos um vídeo que aprofunda as razões pelas quais o Pandas é uma das bibliotecas mais tradicionais do Python. Assista abaixo:
Como funciona a biblioteca pandas em Python na prática?
A espinha dorsal do Pandas reside em duas estruturas de dados primárias e super importantes: as Series e os DataFrames.
Para entender como elas funcionam, vamos usar um exemplo clássico da Ciência de Dados: o conjunto de dados Iris, que contém informações sobre diferentes espécies de flores de Íris.
Series: a coluna de dados do Pandas
Pense em uma Series como uma coluna de dados. É um objeto unidimensional, semelhante a um array, mas com um diferencial crucial: ele possui um índice (index), que é um rótulo que identifica cada registro.
Vamos imaginar que no nosso conjunto de dados Iris, isolamos uma das variáveis, como o comprimento da pétala (PetalLengthCm).
Uma Series representaria essa única coluna, mostrando o comprimento da pétala para cada flor, com um índice numérico ao lado. Na visualização típica do Pandas, a coluna de números à esquerda é o índice, e os valores à direita são os dados em si.
0 1.4
1 1.4
2 1.3
3 1.5
4 1.4
...
145 5.2
146 5.0
147 5.2
148 5.4
149 5.1
Name: PetalLengthCm, Length: 150, dtype: float64 Na saída acima, a coluna de números à esquerda é o índice, e os valores à direita são os dados em si.
No final, o Pandas apresenta algumas informações adicionais, como o nome da Series, a quantidade de elementos (Length) e o tipo de dados (dtype).
DataFrames: a tabela de dados do Pandas
Agora, se uma Series é uma coluna, um DataFrame é uma tabela completa. Ele é um objeto bidimensional, de tamanho variável, onde os dados são organizados em linhas e colunas. Pense nele como uma união de várias Series que compartilham o mesmo índice, formando assim uma estrutura tabelar.
Um DataFrame é como uma planilha do Excel, mas com muito mais poder e flexibilidade para manipulação programática. A estrutura de um DataFrame se parece com isso:
| Índice | Comprimento da Sépala | Largura da Sépala | Comprimento da Pétala | Largura da Pétala | Espécie |
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Setosa |
| ... | ... | ... | ... | ... | ... |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | Virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | Virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | Virginica |
Com o Pandas, essas estruturas podem ser criadas a partir de tipos de dados nativos do Python (como listas, arrays do NumPy e dicionários) utilizando os métodos pandas.DataFrame() e pandas.Series().
Mas o grande trunfo é a capacidade de ler e escrever dados em uma infinidade de formatos de arquivo, incluindo:
- CSV (Comma Separated Values)
- Planilhas do Excel
- Parquet
- SQL (bancos de dados)
- HTML
- JSON (JavaScript Object Notation)
- XML (Extensible Markup Language)
- E muitos outros!
Essa flexibilidade torna o Pandas uma ponte para praticamente qualquer fonte de dados que você possa imaginar.
Pandas Python vs. Excel: qual a diferença e quando usar cada um?
Muitas pessoas, acostumadas com o onipresente Microsoft Excel, se perguntam: "Por que usar Pandas se já tenho o Excel?".
Embora ambos lidem com dados em formato tabular, suas propostas e capacidades são distintas e complementares.
Uma diferença fundamental é a natureza do software: o Pandas é uma solução de código aberto, livre e gratuita, enquanto o Excel é um produto proprietário do pacote Microsoft Office.
Mas a diferença mais marcante surge quando lidamos com grandes volumes de dados.
Diferenças na prática
No Excel, você enfrenta limites de 1.048.576 linhas por 16.384 colunas. Para a maioria dos usos domésticos ou pequenos negócios, isso é mais do que suficiente.
No entanto, em um cenário de Big Data, onde conjuntos de dados podem ter milhões ou até bilhões de registros, esses limites são facilmente ultrapassados.
Com o Pandas, a limitação é baseada principalmente na quantidade de memória RAM disponível no seu computador.
Isso significa que você pode trabalhar com uma quantidade significativamente maior de linhas e colunas, desde que sua máquina consiga alocar a memória necessária.
Essa capacidade é crucial para projetos que envolvem análise de grandes bases de dados, algo cada vez mais comum no dia a dia.
Integralização entre Pandas e Excel
Ainda assim, não precisamos escolher um em detrimento do outro! A beleza está na compatibilidade.
O Pandas oferece excelente integração com arquivos do Excel, permitindo que você leia, manipule e até escreva dados de volta para planilhas Excel.
Isso significa que você pode usar o Excel para entrada de dados ou relatórios básicos e, quando a análise se torna mais complexa ou os dados maiores, migrar para o poder programático do Pandas.
Como o Pandas é utilizado no dia a dia de um cientista de dados?

No cotidiano de um cientista de dados, o "python pandas" é frequentemente utilizado em conjunto com notebooks interativos Python, como o Jupyter Notebook (no qual o Google Colab também se baseia).
Qual é a vantagem disso? A ideia principal é aproveitar a excelente apresentação do código e de suas saídas.
Você escreve um pedaço de código, executa-o imediatamente e já observa o resultado.
Essa interatividade é perfeita para a análise exploratória de dados, onde você testa hipóteses, visualiza amostras e refina sua abordagem passo a passo.
Embora os Jupyter Notebooks sejam a escolha preferida para muitas tarefas interativas, você também pode usar o Pandas em scripts Python comuns (arquivos .py).
A principal diferença é que a saída de todos os fragmentos de código em um script tradicional aparecerá no terminal, uma após a outra, em um formato mais "cru" (raw), sem a mesma riqueza visual e interatividade dos notebooks.
Se você quer aprofundar um pouco mais sobre o uso do Jupyter Notebook, um ambiente que potencializa o trabalho com Pandas, confira o episódio a seguir do Hipsters Ponto Tube!
A cientista de dados Mikaeri Ohana e o Paulo Silveira, CEO da Alura, conversam sobre como uma pessoa Cientista de Dados utiliza essa ferramenta no dia a dia:
O que é Jupyter Notebook? | Hipsters Ponto Tube
Como instalar o pandas no Python: passo a passo para instalar a biblioteca pandas
Chegou a hora de colocar a mão na massa! Para começar a usar essa poderosa "biblioteca pandas python", você precisará instalá-la em seu ambiente Python.
Existem duas maneiras principais e recomendadas: usando a distribuição Anaconda ou o gerenciador de pacotes PIP. Vamos explorar ambas.
Opção 1: instalando com Anaconda (recomendado para iniciantes)
A maneira mais fácil e simples de "instalar pandas python", especialmente se você está começando na Ciência de Dados, é através da instalação da distribuição Anaconda.
O Anaconda é um ambiente de desenvolvimento completo, pensado para Ciência de Dados com Python e linguagem R.
Ele já vem com uma vasta coleção de bibliotecas e softwares populares no ramo, pré-instalados e configurados para funcionarem juntos. E sim, o Pandas já vem incluído!
Vale lembrar que, ao instalar a biblioteca pandas por meio do Anaconda, você também já instala outras bibliotecas, como o NumPy, Scikit-learn, Jupyter Notebook, Spyder, e muitas outras ferramentas essenciais, tudo em um pacote só. Isso simplifica muito a configuração inicial do seu ambiente.
Você pode aprender como instalar o Anaconda no Windows, macOS ou Linux através da documentação oficial do Anaconda. Siga o guia para o seu sistema operacional e você terá o Pandas pronto para usar em poucos minutos.
Opção 2: instalando com PIP (gerenciador de pacotes do Python)
Se você já tem o Python instalado em sua máquina e prefere uma abordagem mais minimalista, pode usar o PIP, o sistema de gerenciamento de pacotes do Python.
Pré-requisitos:
- Python: Certifique-se de ter o Python instalado em sua máquina, baixado dosite oficial.
- PIP: Geralmente, o PIP já vem instalado com as versões mais recentes do Python. No entanto, vamos verificar e, se necessário, instalá-lo ou atualizá-lo.
Passo a passo para instalar o Pandas com PIP:
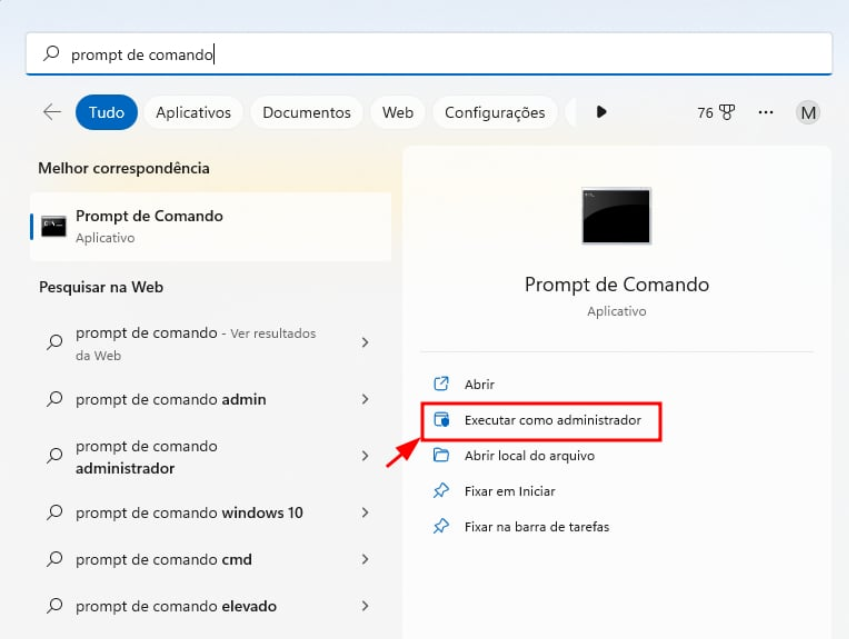
1. Abra o Prompt de Comando (Windows) ou Terminal (Linux/macOS):
- Windows: Pressione as teclas Windows + R, digite "cmd" ou "Prompt de Comando" e clique em "Executar como administrador" para abrir com permissões elevadas.
- Linux/macOS: Abra o aplicativo "Terminal".
Verifique a versão do Python (é opcional, mas recomendado): É uma boa prática garantir que você está usando a versão correta do Python. Digite o seguinte comando e pressione Enter:
2. Você deve ver uma saída como Python 3. 14.3 (o número da versão pode variar).
Bash
python --version Verifique e atualize o PIP (se necessário): Se o PIP não estiver instalado ou se você quiser garantir que ele esteja atualizado, use o comando:
Bash
python -m ensurepip --upgrade3. Isso instalará ou atualizará o PIP para a versão mais recente.
Instale o Pandas! Agora que temos o PIP pronto, o comando para instalar o pandas no python é bem simples:
Bash
pip install pandas4. Pressione Enter e aguarde. O PIP fará o download da "biblioteca pandas python" e de suas dependências. Se a instalação for bem-sucedida, você verá uma mensagem indicando isso.
Pronto! Agora você tem a biblioteca pandas instalada em seu Python e está apto a trabalhar com análise de dados, manipulação de informações e muitas outras tarefas com o pandas python.
Atenção ao detalhe da instalação!
Caso você tenha mais de um disco rígido ou múltiplas instalações de Python na sua máquina, é muito importante garantir que o Pandas esteja sendo instalado na mesma instância do Python que você pretende usar.
Se você usa py ou python3 em vez de python para chamar seu interpretador, use o mesmo prefixo para os comandos do pip (ex: python3 -m pip install pandas).
Quer dar os primeiros passos na análise de dados com Python e trabalhar em projetos reais?
Quer saber como instalar a biblioteca pandas na prática e colocar o pandas python em ação em projetos reais?
Acesse nosso conteúdo exclusivo de Imersão Dados com Python e veja na prática passo a passo de como instalar a biblioteca pandas, manipular dados e criar análises de alto impacto utilizando pandas python.
Como aprender mais sobre o tema?
O Pandas é mais do que apenas uma biblioteca; é uma porta de entrada para um universo de possibilidades na análise e manipulação de dados, capacitando você a extrair insights e tomar decisões mais informadas.
Se você já deu seus primeiros passos e quer ir além, te convidamos a participar dos Challenges de Data Science. Essa é a oportunidade ideal para construir um portfólio de projetos reais, desenvolvendo habilidades práticas em limpeza, tratamento, visualização de dados e até Machine Learning.
Agora, se o seu objetivo é uma evolução completa, lembre-se que o Pandas é apenas o começo.
Na Carreira em Ciência de Dados da Alura, você não estuda tópicos isolados. Você percorre um mapa de aprendizado com clareza e consistência, dominando as ferramentas que o mercado mais valoriza através de uma sequência de cursos e checkpoints feita para o seu nível de domínio.
Iniciar minha jornada na Carreira em Ciência de Dados
O futuro dos dados espera por você!
FAQ | Dúvidas frequentes sobre o pandas python e a biblioteca pandas em Python
1. O Pandas funciona bem para projetos grandes de Machine Learning?
Sim. Embora o Pandas não seja a biblioteca usada para treinar modelos, ele é excelente para pré-processamento, limpeza, seleção de features, junções e transformações, que são etapas essenciais antes de passar os dados para bibliotecas como Scikit-Learn, XGBoost ou TensorFlow. Porém, para datasets extremamente grandes (de dezenas de GB ou mais), é comum migrar para soluções como Dask, Polars ou Spark.
2. Preciso saber programação antes de aprender Pandas?
Você não precisa ser especialista, mas é importante ter uma base mínima em Python, entender variáveis, listas, dicionários, funções e lógica básica. Sem isso, aprender Pandas pode ser frustrante, porque a biblioteca é poderosa, mas exige manipulação programática.
3. O Pandas é usado fora da área de dados?
Sim! Além de cientistas e analistas de dados, usam Pandas:
- engenheiros de software (para ETL e logs),
- profissionais de finanças,
- pesquisadores acadêmicos,
- profissionais de marketing e BI,
- analistas de RH e operações.
Sempre que existe uma planilha ou tabela para analisar, Pandas pode ser útil.
Até mais!